
Introduction
Description
Building data pipelines in Databricks used to mean a lot of notebook logic, Spark code, and manual orchestration.
In this course you'll learn a more structured and modern approach: build Spark Declarative Pipelines on Databricks using a clean Bronze → Silver → Gold (Medallion) architecture, where you define what you want with SQL and Databricks handles execution, dependencies, and orchestration. Also, orchestrate and operate them with the new Lakeflow Designer.
You can follow the entire course using the Databricks Free Edition, without needing a paid setup.
This is a fully hands-on course. You’ll start with a raw e-commerce dataset, ingest it into Delta Lake, progressively refine it into analytics-ready tables, and then run and manage the entire pipeline through Lakeflow’s visual interface.
Along the way, you’ll understand how Delta Lake ensures reliability, how Unity Catalog provides governance and lineage, and where Genie, the Databricks Assistant, naturally supports pipeline development.
By the end of this course, you’ll be able to design structured, production-ready data pipelines on Databricks. Not just transformations inside notebooks, but end-to-end declarative workflows that can be scheduled, monitored, and extended.
What You’ll Build in This Course
A Modern Databricks Pipeline Mental Model
You’ll start by understanding the new way of building pipelines in Databricks.
Instead of writing every step manually, you define the target tables and transformations with SQL. Databricks then handles dependencies, execution order, incremental processing, and orchestration.
You’ll learn how this fits together with the Bronze, Silver, and Gold structure and why this is much cleaner than having a lot of transformation logic spread across notebooks.
You’ll also use notebooks, SQL, visualizations, and Genie Code to explore the raw dataset before building the actual pipeline, all within the Databricks Free Edition.
Delta Lake & Unity Catalog Foundations
Before building the pipeline, you’ll learn the foundations that make Databricks reliable.
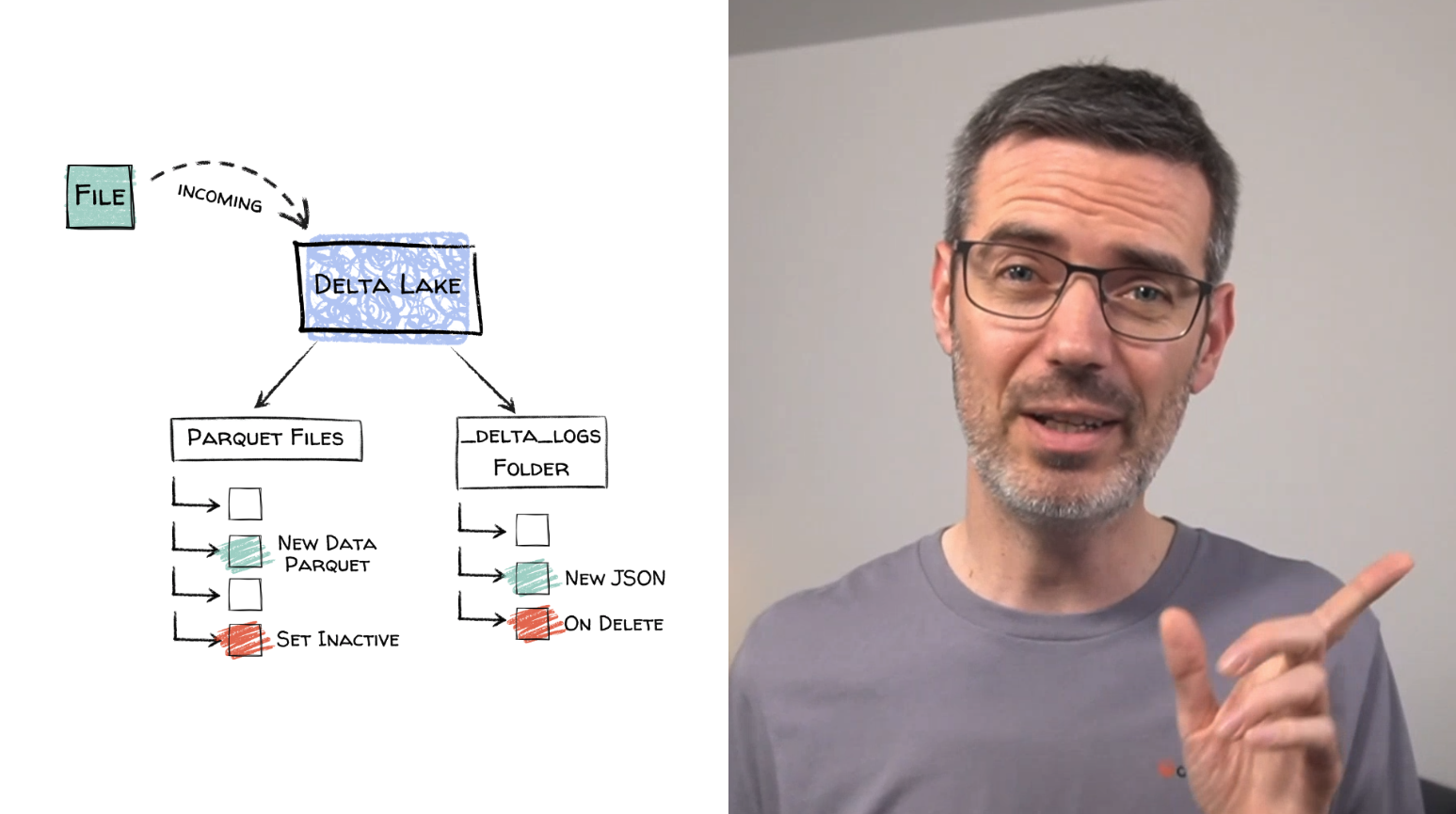
You’ll see how Delta Lake gives you ACID transactions, schema enforcement, versioning, and time travel. This is important because pipelines should be reproducible and safe, especially when data changes or something goes wrong.
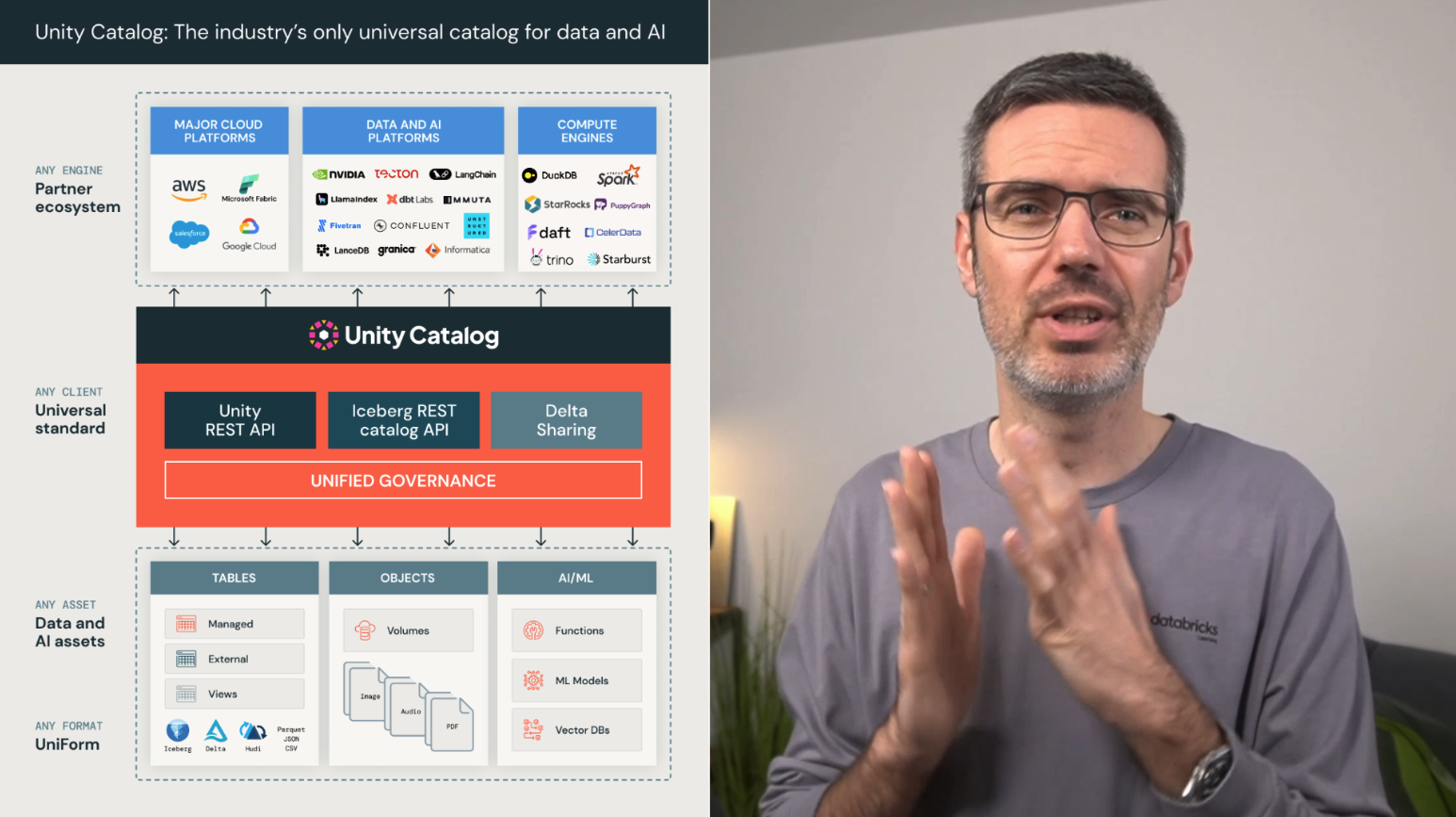
You’ll also get to know Unity Catalog and understand how catalogs, schemas, tables, and volumes are organized. You’ll see how governance, access control, lineage, and discovery fit into pipeline design from the beginning.
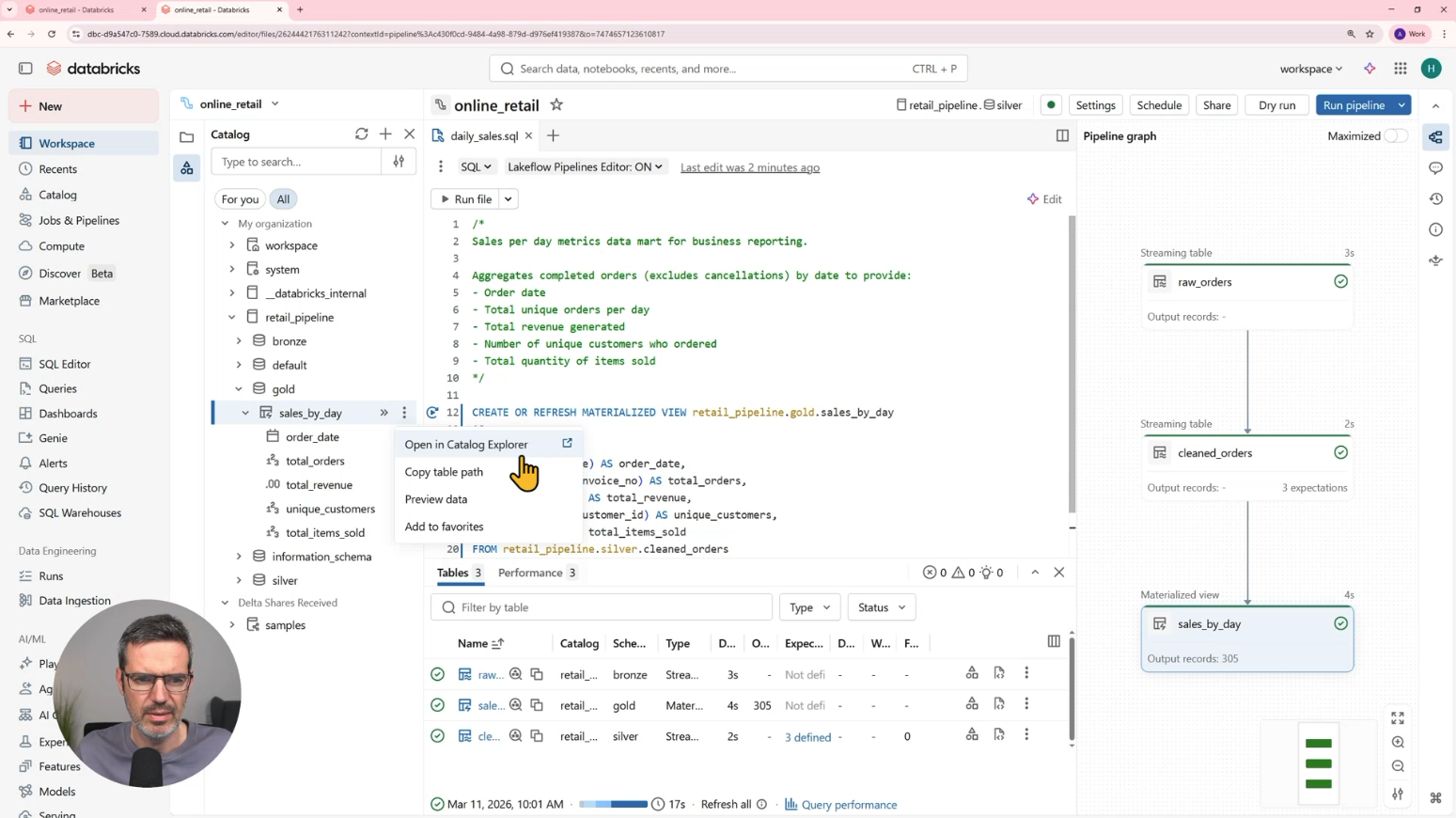
Building Bronze, Silver, and Gold Layers with Spark Declarative Pipelines
Then you’ll build a complete medallion pipeline with a real e-commerce dataset.
In Bronze, you’ll ingest raw data into a streaming table and preserve the source structure.
In Silver, you’ll clean and standardize the data. You’ll fix column names, cast data types, convert timestamps, calculate new fields, handle cancellations, and add expectations for data quality checks.
In Gold, you’ll create a business-facing materialized view for daily sales metrics. You’ll aggregate orders, revenue, customers, and sold items, and you’ll query and visualize the result directly in Databricks.
All of this is done with SQL using Spark Declarative Pipelines.
Scheduling & Operating the Pipeline
Once the pipeline works, you’ll turn it into something that runs automatically.
You’ll schedule the pipeline with Databricks Jobs, configure notifications, monitor runs, and simulate new incoming data to verify that Bronze, Silver, and Gold update correctly.
This is where the pipeline moves from development to something closer to operations.
Visual & No-Code Pipeline Building with Lakeflow Designer
After building the SQL-based declarative pipeline, you’ll move into Lakeflow Designer.
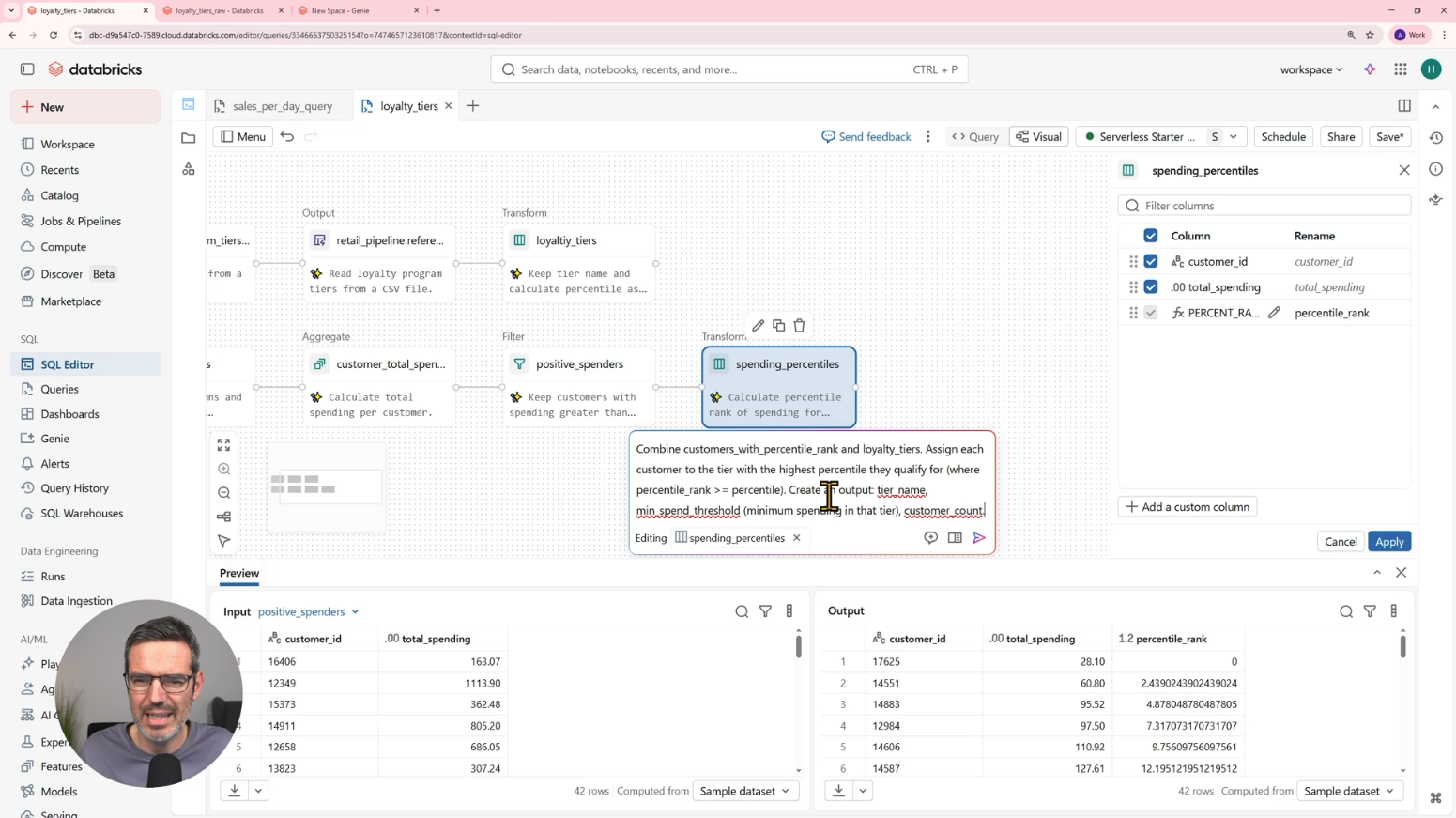
Here you’ll see how pipelines can be built visually with a canvas, drag and drop components, and natural language instructions with Genie.
You’ll build a customer loyalty tier use case. You’ll load a tier definition file, calculate customer spending, assign percentile ranks, combine the data, and create output tables.
The important part: Lakeflow Designer generates the underlying SQL and pipeline logic. So analysts can build visually, while engineers can still review and improve the generated logic.
Bonus: Streaming with Declarative Pipelines
This part goes beyond the Databricks Free Edition and shows what’s possible in a more production-like setup.
To extend the model beyond batch processing, I’ll show you how streaming pipelines work in Databricks.
You’ll see how to connect Databricks to AWS Kinesis, ingest sensor readings into Bronze, process them into Silver, and classify sensor status.
I’ll also show you how the same pipeline behaves in triggered mode and continuous mode, so you understand the difference between incremental batch processing and near real-time processing.
Who This Course is For
This course is for Data Engineers and Analytics Engineers who want to:
- build structured Bronze/Silver/Gold pipelines in Databricks
- use Spark Declarative Pipelines with SQL
- understand Delta Lake fundamentals in a practical context
- use Unity Catalog correctly for governance and organization
- move from notebook-based transformations to declarative workflows
- explore visual and almost no-code pipeline building with Lakeflow Designer and Genie
- explore how streaming integrates into declarative pipeline design
No prior experience with Spark Declarative Pipelines or Lakeflow Designer is required. You’ll learn everything step by step while building a complete end-to-end pipeline.
Course Curriculum
Start Now:
Spark Declarative Pipelines & Lakeflow Designer on Databricks will be included in our Data Engineering Academy and also available as Free Lab

